








Não seria sensacional aumentar a capacidade de entrega de projetos de Data Science para subsidiar as decisões das área de negócio da empresa?
Vamos ver como isso é exequível utilizando uma plataforma para desenvolver e produtizar projetos de Data Science com alta performance e como resultado gerar insumo para uma área de MKT ou de retenção de cliente desenvolver ações para o negócio.
As etapas que serão apresentados, irão mostrar na prática como entregar projetos de AI de alto desempenho para áreas de negócios. Envolvendo as etapas:
- Ingestão e consumo de Big Data na nuvem utilizando Azure Blob Storage.
- Algoritmos de Machine Learning com PySpark e H2O com alta performance.
- Deploy – Aplicar o modelo com processamento remoto no Databricks.
- Disponibilizar os resultados em Dashboard Power BI ou Tableau para áreas de negócio.
Para este exemplo vamos aplicar modelos de Machine Learning para identificar a probabilidade de um cliente não pagar a próxima fatura. No entanto, o foco aqui não é discutir o processo de análise de dados, mas sim, apresentar um overview de um processo de Data Science e ML utilizando computação distribuída na nuvem de forma simples mas mantendo uma alta performance.

- Processamento de dados no Databricks
O que é Databricks? É uma ferramenta de Analytics em nuvem para gerenciamento e processamento de Big Data, que permite a construção de pipelines de dados e modelos de machine learning em um sistema distribuído de alta performance.
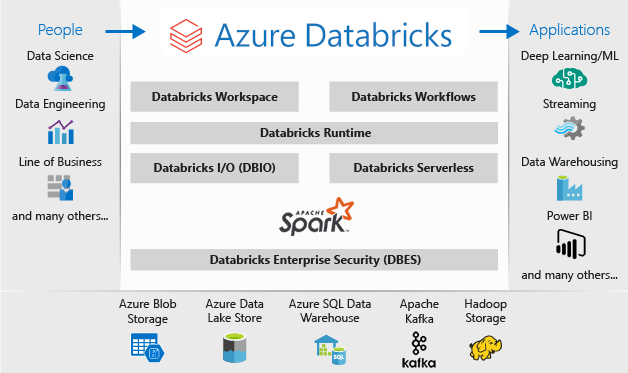
Neste exemplo conectamos em um cluster com Databricks hospedado na Azure, mas este cluster poderia estar hospedado em outra nuvem, como por exemplo AWS.
Para desenvolver esta conexão com o Databricks e orquestrar o processamento dos algoritmos de Machine Learning foi utilizado o KNIME Analytics Platform.
O KNIME é um software para criar, automatizar e produtizar análise e ciência de dados, através de um ambiente fácil e intuitivo.
Dentre as várias funcionalidades, a plataforma possibilita:
– Acesso às diversas fontes de dados;
– O desenvolvimento e deploy de algoritmos de Machine Learning;
– A conexão com diversas plataformas de Big Data e IA local ou na nuvem, alem do Databricks, por exemplo, Google BigQuery, Hadoop, Amazon Redshift e S3.
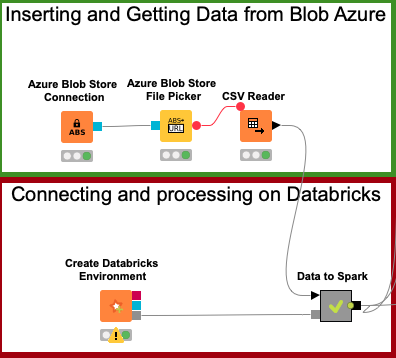
- Training Machine Learning Model
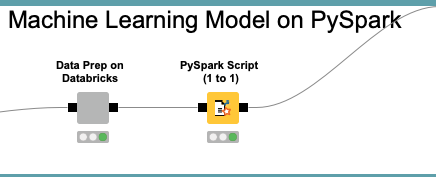
Um vez que os dados estão agora no Databricks, vamos então processar os algoritmos de Machine Learning.
Os algoritmos de Machine Learning foram construídos utilizando o H2O Sparkling Water e o PySpark, com o objetivo de predizer a probabilidade de um determinado cliente não pagar a próxima fatura.
O processamento desses algoritmos no Databricks orquestrado pelo KNIME ocorreu na nuvem, de forma distribuída, possibilitando que a aplicação seja rápida e escalável.

No H2O foi treinado o Gradient Boosting Machine Learning (GB) for Classification. Este método cria árvores de decisão sequenciais de forma paralela.
Ao final do treinamento e teste do algoritmo, o modelo foi exportado para o Mojo (Model Object Optimized).
Já no PySpark foi escrito um script para treinar o algoritmo Random Forest, cujo modelo cria um conjunto de árvores de decisão com processamento interativo. Após o treinamento, o modelo foi exportado para Spark MLlib model.

Para ambos os modelos foram calculados AUC (Area under the ROC Curve) para identificar qual dos algoritmos apresenta a melhor performance. Valores próximos de 1 indicam modelos com melhor performance, já valores próximos a 0 significa que o modelo apresentou baixa performance em sua capacidade preditiva.
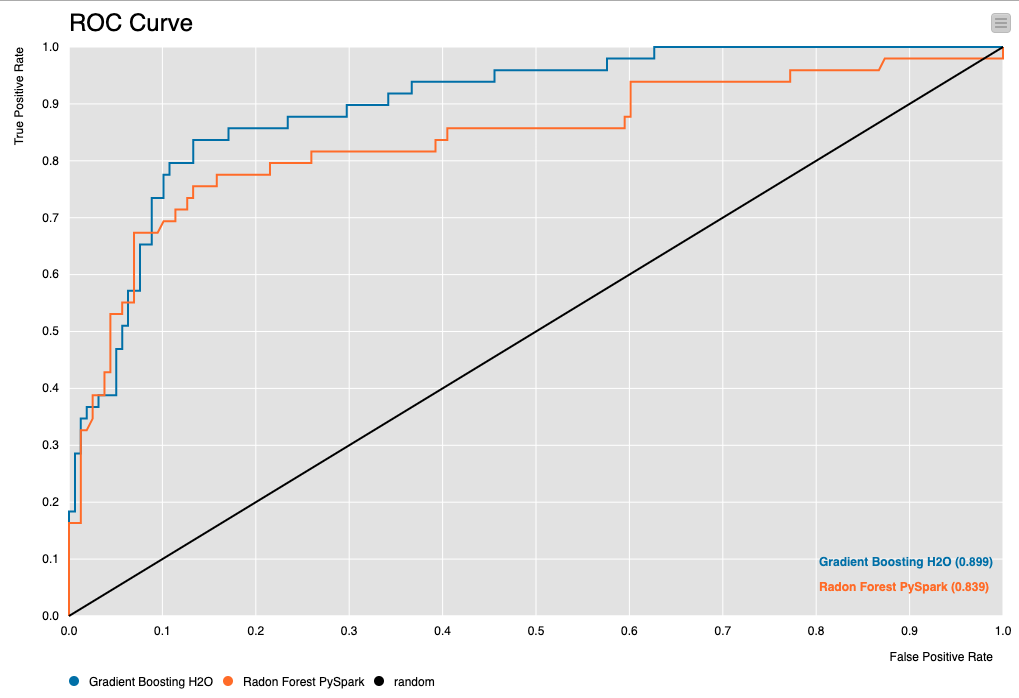
Quando comparada as AUCs gerada pelos algoritmos, verifica-se que ambos tiveram um desempenho muito semelhante. No entanto, houve uma pequena vantagem na performance do GB no H2O sob o Random forest no Pyspark.
Por isso, o GB foi o modelo utilizado aplicado e predizer a probabilidade de um determinado cliente não pagar a próxima fatura. Este processo é denominado Deploy.
- Deploy – Aplicar o modelo com processamento remoto no Databricks.
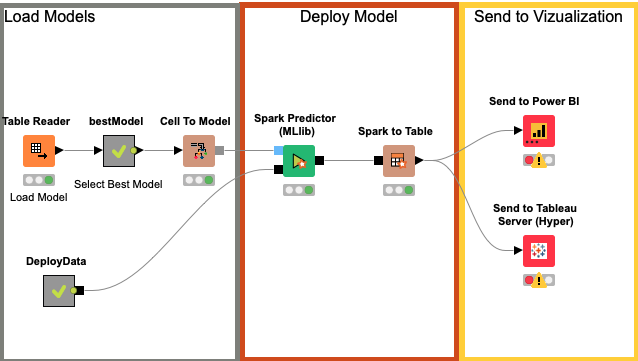
No processo de Deploy as estruturas dos modelos são carregados. Em seguida, seleciona-se automaticamente aquele que apresenta a melhor performance. Em paralelo, é feita a leitura do novo conjunto de informações contendo os dados dos clientes dos quais se deseja obter as probabilidades de pagamento. Por fim, é aplicado o algoritmo selecionado utilizando o Spark no Databricks para efetuar os cálculo e obter as probabilidades.
- Disponibilizar os resultados em Dashboard Power BI ou Tableau para áreas de negócio.
Por fim, este resultado pode ser visualizado no próprio KNIME ou enviado para um Dashboard como por exemplo Power BI ou Tableau uma vez com o KNIME tem integração direta com estas ferramentas de BI.

Desta forma, o processamento, a escolha do modelo, a leitura dos novos dados, a predição de um cliente não pagar a fatura e a visualização dos resultados estão sendo realizados automaticamente num ambiente de computação distribuída na nuvem com alta performance.
Possibilitando entregar indicadores provenientes de uma aplicação de AI para subsidiar ações das áreas de negócio.
Por Marcus Estanislao
